Related Content
About



Recently, artificial intelligence (AI) technologies, represented by foundation models, have witnessed a rapid advancement, which led to a surge in power demand. According to the Artificial Intelligence Index Report 2023 released by the Stanford Institute for Human-Centered AI, a single training run of the GPT-3 language model consumed 1,287 megawatt-hours of electricity, approximately equal to the total energy required for 3,000 Tesla electric vehicles to travel 200,000 miles each. It's predicted that by 2030, annual electricity consumption for intelligent computing will reach 500 billion kilowatt-hours, accounting for 5% of the world's total power generation.
Energy consumption is calculated by the formula: Energy Consumption = Computational Load/Energy Efficiency. Enhancing the energy efficiency of hardware and reducing the computational load of models are key to developing energy-efficient hardware for foundation models. In terms of energy efficiency, traditional hardware is plagued by substantial data movement during computation, thereby restricting the improvements in computational efficiency. Take DeepSeek for instance, over 40% of computation time is spent on processing memory-intensive operators, reducing hardware utilization and increasing computational costs. Computing-in-memory (CIM) technology enables in-situ or near-data processing, significantly reducing data movement and greatly enhancing energy efficiency. NVIDIA's Blackwell-architecture GPUs utilize CIM to achieve a 30-fold increase in foundation model inference performance while reducing cost and energy consumption by a factor of 25. Regarding computational load, constrained by the scaling law, the marginal benefits of increasing model size are declining because of high model complexity with excessive parameters and computational demands. Developing low-complexity models or operators to reduce computational demands of foundation models is also crucial for lowering energy consumption, yet this challenge remains insufficiently explored.
To address these challenges, a research team from Zhejiang Lab (ZJ Lab) for the first time introduced a novel feature learning approach from the perspective of hardware-algorithm co-design, based on the physical properties of memristor-based CIM hardware. By combining high-efficiency hardware with low-computation models, this approach reduces energy consumption by approximately four to five orders of magnitude compared to conventional hardware. Memristor-based CIM hardware, a cutting-edge topic in AI research, offers significant advantages such as high energy efficiency, low cost, and strong radiation resistance. Previous research by the team demonstrated that CIM chips can achieve key energy efficiency metrics comparable to leading international mainstream chips at less than 1% of the cost. This method leverages the drift-diffusion kinetics (DDK) of individual memristor devices to extract and learn spatiotemporal features from input signals, dramatically reducing model parameters and computational load. The team also introduced a hybrid training approach that combines off-chip pre-training with in-situ training, enhancing network convergence speed and recognition accuracy. This method has been successfully implemented on a 180-nm chip for tasks ranging from speech to point cloud classification. Experimental results show that for text recognition tasks, the network achieves an accuracy of 91.2%, 0.7% higher than transformer models, while reducing parameters and computational load by approximately 152-fold and 631-fold, respectively. Moreover, energy consumption is reduced by four to five orders of magnitude, and chip area is reduced by three orders of magnitude compared to existing chips. This work for the first time validates the disruptive "device physics as algorithms" approach, offering a new paradigm for foundation model development and laying a crucial hardware foundation for future energy-efficient AI.
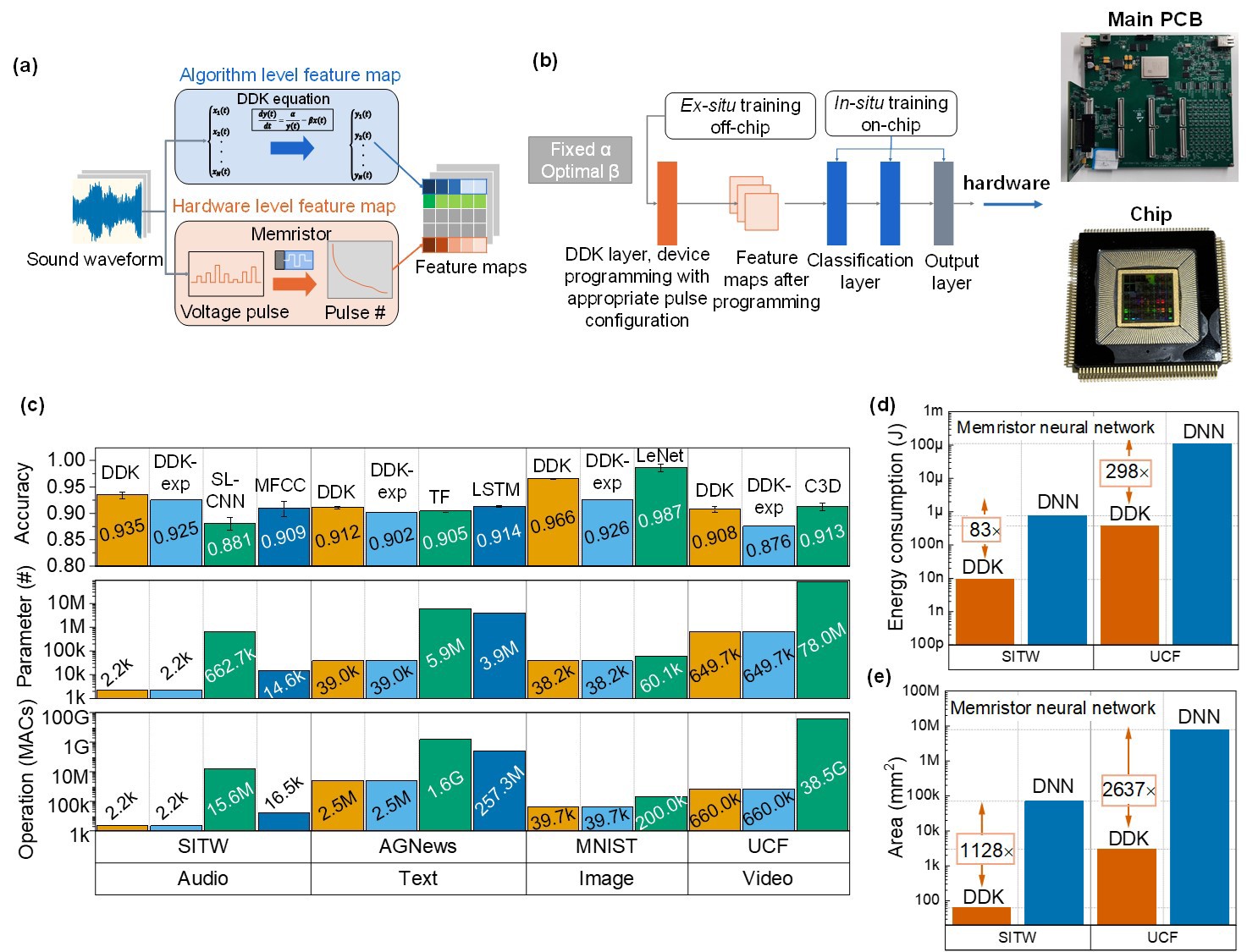
Figure 1 (a) Feature learning approach leveraging the drift-diffusion kinetics of computing-in-memory devices. (b) Hybrid training approach for neural networks and the hardware system employed in the experiments. (c) Performance comparison of this approach with other feature learning techniques across speech, text, image, video, and 3D object recognition tasks. (d) Hardware energy consumption (d) and chip area (e) comparison between the memristor-based DDK network and the memristor-based DNN.
The research findings have been published in Nature Communications titled "Memristor-based feature learning for pattern classification". SHI Tuo, a research expert at ZJ Lab, is the first author of the paper. Professor YAN Xiaobing from Hebei University and Professor LIU Qi from Fudan University are the corresponding authors. ZJ Lab is the first affiliation of the paper.
Article link: https://www.nature.com/articles/s41467-025-56286-y


Related Content
Office of Global Engagement
Follow us
Visit Us